Convolutional Neural Network
Convolutional neural networks (convnets, CNNs) are a powerful type of neural network that is used primarily for image classification. CNNs were originally designed by Geoffery Hinton, one of the pioneers of Machine Learning. Their location invariance makes them ideal for detecting objects in various positions in images. Google, Facebook, Snapchat and other companies that deal with images all use convolutional neural networks.
Convnets consist primarily of three different types of layers: convolutions, pooling layers, and one fully connected layer. In the convolutional layers, a matrix known as a kernel is passed over the input matrix to create a feature map for the next layer. The dimensions of the kernel can also be adjusted to produce a different feature map, or to expand the data along one dimension while reducing its size along the other axes. Sometimes, values on the feature map are computed by taking the sum of the result of an element-wise multiplication of the kernel and an appropriately sized section of the input matrix. Often, a dot product is used instead of the element-wise multiplication, but this can be modified for better (or worse) results. Another technique to improve CNNs is to use multiple kernels in a given convolutional layer and concatenate the results to create the feature map. The fact that one kernel is used for the entire image makes convolutional neural networks very location-invariant and prevents them from overfitting. Here is an example of a convolution:

You can see how the filter maps a set of points from the input matrix to a single node in the next layer. Here is a more low-level diagram of a convolution:
 This convolution takes the sum of the element-wise product of the filter and a chunk of the input. The filter used in the diagram could be used for sharpening an image because it boosts the value of pixels that are different from their neighbors. When training a CNN, the network may learn filters like this one to extract meaningful information from images.
This convolution takes the sum of the element-wise product of the filter and a chunk of the input. The filter used in the diagram could be used for sharpening an image because it boosts the value of pixels that are different from their neighbors. When training a CNN, the network may learn filters like this one to extract meaningful information from images.
Next, a pooling layer is applied to the feature map produced by the convolution. Max pooling, the most common type of pooling, simply means taking the maximum value from a given array of numbers. In this case, we split up the feature map into a bunch of \(n\times n\) boxes and choose only the maximum value from each box. Here is what that looks like:

The final layer of a convolutional neural network is called the fully connected layer. This is a standard neural network layer in which some nonlinearity (ReLu, tanh, sigmoid, etc.) is applied to the dot product of an input and a matrix of weights. Then a softmax function can convert the output into a list of probabilities for classification.
Convolutional neural networks usually have far more than just three layers. Convolutions and max-pooling layers can be stacked on top of each other indefinitely for better results. Here is an image of a very deep convolutional neural network with many layers:

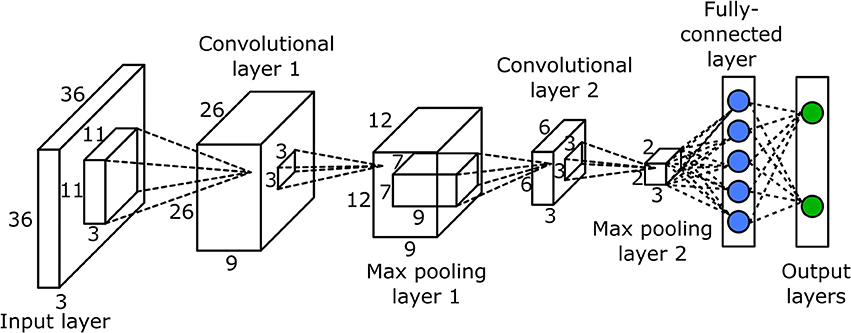
Convolutional neural networks are most commonly used for image classification. Their location invariance makes them ideal for detecting objects in various positions in images. Google, Facebook, Snapchat and other companies that deal with images all use convolutional neural networks. Another less common use for CNNs is text classification. A list of Word2Vec or Glove embeddings may be used as the input for a CNN, which could be trained to recognize sentiment or some other classification.
Convolutional neural network(CNN) have large applications in image and video recognition, to recognize a car by deep learning model refer to Understanding CNN with an example to recognize car