DNA
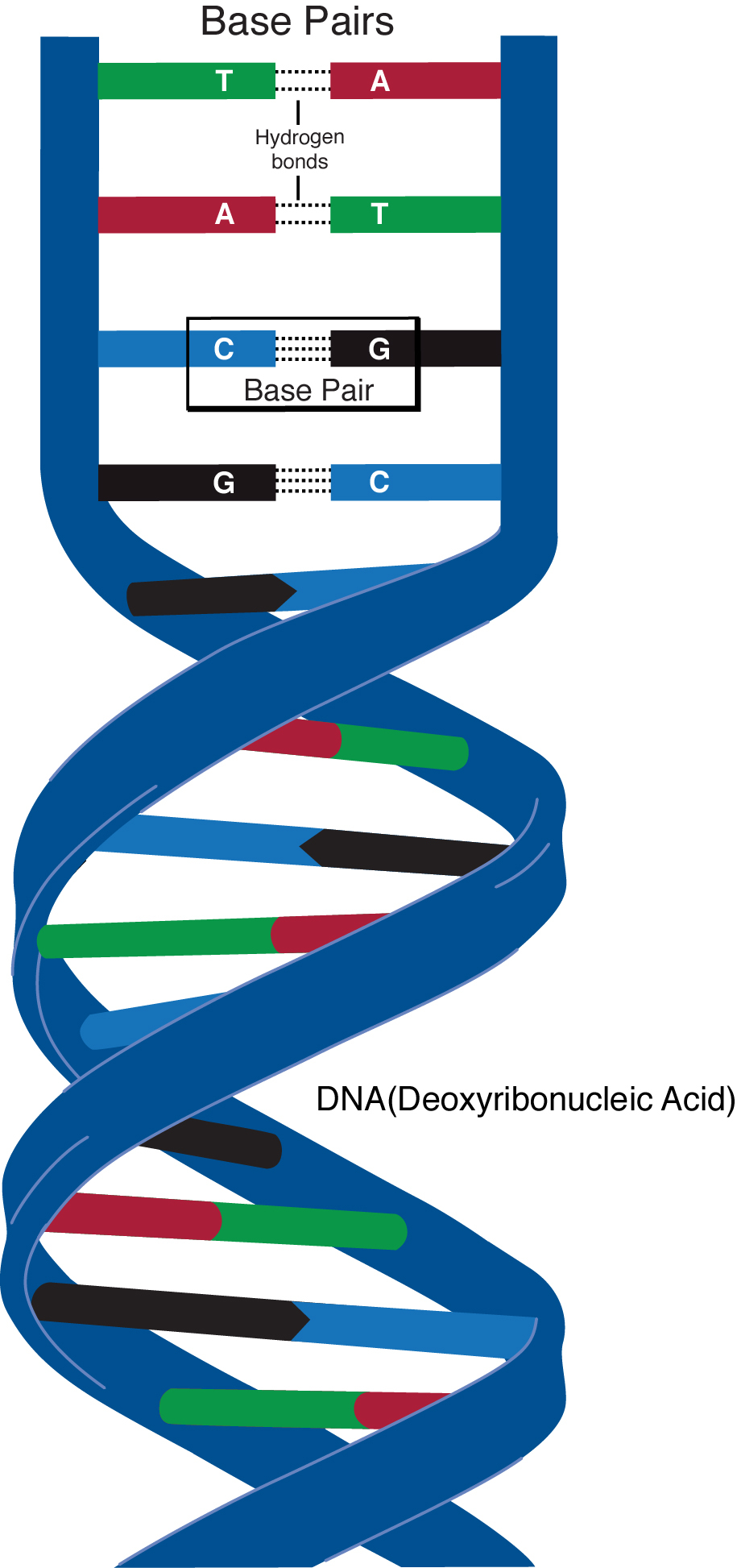
Deoxyribonucleic acid (DNA) is the biomolecule that contains the genetic information in all organisms. In other words, DNA is an organism's "blueprint." DNA differentiates one species from another and also determines what makes each individual unique within a species. A person's DNA determines that he has the same general body and brain structure as other humans. DNA also determines whether his eyes are blue and which hand he favors when writing. DNA determines what characters he shall inherit from his parents and any genetic similarities between him and his ancestors.
Increasingly, medical science is using DNA to understand the causes of diseases and birth defects. Research involving DNA is used in both prevention and treatment of a variety of illnesses, ranging from cystic fibrosis to cancer.
DNA is present in all body fluids, making it an important element in the modern justice system. If blood, saliva, hair, or semen is found at a crime scene, it can be accurately matched to a suspect.
Additionally, since DNA is inherited from one's parents, it can be used to determine how closely two people are related to each other. A father can confirm his paternity of a child, or two people who were adopted at birth can determine if they are siblings.
Every cell in a human body contains that individual's entire genome, though any one cell will only use a tiny fraction of the information it contains. The special structure of DNA ensures that genetic information can be replicated in new cells and passed from parent to offspring.
Contents
DNA Structure
The monomer of DNA is the deoxyribonucleotide, a subset of nucleotides. Each deoxyribonucleotide includes a pentose sugar deoxyribose, bonded to both a phosphate group at the 5' end and a nitrogenous base at the 1' carbon. Two types of bases are found in DNA: pyrimidines and purines. The pyrimidines, cytosine (C) and thymine (T), are single-ringed structures. Adenine (A) and guanine (G) are purines and contain a double ring. These four bases are the building blocks of DNA.
![cytosine [1]](https://ds055uzetaobb.cloudfront.net/brioche/uploads/wcZ5PrWcTk-cytosine.png?width=1200) cytosine [1]
cytosine [1]
![thymine [1]](https://ds055uzetaobb.cloudfront.net/brioche/uploads/MEgQKpnXkq-thymine.png?width=1200) thymine [1]
thymine [1]
![adenine[1]](https://ds055uzetaobb.cloudfront.net/brioche/uploads/BEjiz2S5rE-adenine.png?width=1200) adenine[1]
adenine[1]
![guanine[1]](https://ds055uzetaobb.cloudfront.net/brioche/uploads/xBxGlqH1lH-guanine.png?width=1200) guanine[1]
guanine[1]
Which of the following nucleobase is found in RNA (ribonucleic acid) but not found in DNA (deoxyribonucleic acid)?
DNA usually takes the shape of a double helix, with two strands twisting around each other like a spiral staircase. Each "step" in this staircase is a pair of nucleotides. These two nucleotides are held together by hydrogen bonds and are referred to as a base pair. Normally, adenine forms two hydrogen bonds with thymine, and guanine forms three hydrogen bonds with cytosine. However, mutations can cause incorrect base pairing. Each base pair is bonded to the next base pair (backbone is held together) via phosphodiester bonds between the phosphate of one nucleotide, also called the 5' end, and the 3' end or hydroxyl group of another nucleotide. This makes up the sugar-phosphate backbone.
![[2]](https://d18l82el6cdm1i.cloudfront.net/uploads/DBuYj5TVBW-nucleotide.gif) [2]
Because each nucleotide specifically hydrogen bonds to only one other nucleotide, if the sequence of one strand is known, the sequence of the complementary strand can be re-constructed. DNA is often "read" by looking at one strand of the double helix. Along a strand, DNA is read as a sequence of these four nucleotides, which may look something like this: ATTGCCCTG.
[2]
Because each nucleotide specifically hydrogen bonds to only one other nucleotide, if the sequence of one strand is known, the sequence of the complementary strand can be re-constructed. DNA is often "read" by looking at one strand of the double helix. Along a strand, DNA is read as a sequence of these four nucleotides, which may look something like this: ATTGCCCTG.
The DNA that is found in life forms is usually B-DNA. It is a right-handed double helix with a diameter of 2 nm. Each base pair is separated by 0.34 nm, and there are 10 base pairs per turn of the helix. The sugar-phosphate backbone is not equally spaced, causing it to have a major and minor groove, both of which are about the same depth. Some alternative forms of DNA include A-DNA and Z-DNA. A-DNA, a dehydrated form of DNA, is a right-handed helix with 10.9 base pairs per turn of the helix, a deep narrow major groove, and a shallow wide minor groove. Z-DNA is a left-handed helix with 12 base pairs per turn of the helix, a deep minor groove, and a very shallow major groove.
![A, B, and Z DNA [3]](https://ds055uzetaobb.cloudfront.net/brioche/uploads/caQ6l9VYxC-a-b-z-dna_side_view.png?width=1200) A, B, and Z DNA [3]
A, B, and Z DNA [3]
Complimentary Strands of DNA
What would the complimentary strand of DNA look like for the sequence 5'-ATTGCCCTG-3'?
3'-TAACGGGAC-5'
Why do base pairs contain one purine and one pyrimidine?
By always containing a purine paired with a pyrimidine, the DNA molecule maintains its 2 nm diameter. Two pyrimidines paired to each other would be too narrow to bridge that distance, while two purines would be too wide, distorting the molecule.
The Central Dogma of Molecular Genetics
The primary function of DNA is protein synthesis. The process of DNA to RNA to Protein is called the central dogma of molecular genetics. First, the portion of the DNA strand being used undergoes transcription, where the template strand of DNA is used as a template for a complementary strand of messenger RNA (mRNA). The mRNA travels from the nucleus of the cell to the cytoplasm, where the second step of protein synthesis occurs. Translation involves "reading" the codons of the RNA strand and using the information to assemble a chain of amino acids, called a polypeptide chain. Translation takes place in the ribosomes of cells. Once the polypeptide chain is assembled, it is folded into a functioning protein.
Sixty-four codons can be made from the four nucleotides. Of these, three are "stop" codons that tell the ribosome to stop building and cut the polypeptide chain free so it can fold into its final shape. The other 61 code for amino acids. Since there are only 20 amino acids, there is redundancy in the genetic code. Several codons may code for the same amino acid. For example, AGA and AGG both code for arginine. However, there is no ambiguity in the genetic code. AGG always codes for arginine, never for glycine or valine.
However, sometimes RNA doesn't always become protein. RNA can function on its own sometimes. Such RNAs are called noncoding RNAs. Some examples are miRNAs, piRNAs, snRNAs, and snoRNAs. Such RNAs can function by binding complementarily to sequences in DNA and other RNAs in concert with proteins; these small RNAs help target protein complexes to do their jobs to specific sequences.
Why is transcription necessary? What are the advantages of using RNA as an intermediate rather than making a protein directly from DNA?
The two-step process of transcription and translation may seem overly complicated compared to translating a protein directly from DNA, but the cytoplasm can be thought of as a construction site. Using an RNA intermediate allows the original blueprints for the protein to remain in the nucleus, safe from any damage, but able to be copied as often as necessary. Additionally, multiple copies of the RNA can be used at once. If the construction workers need to build eight doors, they don't have to fight over the blueprints.
DNA Organization and the Genome
Genomic DNA is located in the nuclei of eukaryotic cells in the form of linear chromosomes. When a cell is not undergoing replication, the chromosomes are loose and somewhat disorganized; the DNA and proteins associated are referred to collectively as chromatin. 92% of the genome is euchromatin, which is loosely packed DNA. Active genes tend to be found in euchromatin, and the reasoning behind this is left to the reader to figure out. There is also heterochromatin, which is tightly packed DNA. Typically, genes found in heterochromatin aren't expressed/are expressed in low levels. Heterochromatin can also be found in telomeres and centromeres/other repetitive DNA sequences. When it is time for a cell to undergo replication, DNA is wrapped around nucleosomes, which are "beads" consisting of histone proteins. This is when DNA becomes discernible as linear chromosomes under a microscope.
Eukaryotes also have genes in their organelles and cytoplasm. A circular piece of DNA is found in the mitochondria of animal cells and also in the chloroplasts of plants and algae. A person's nuclear DNA is a combination of both parent's genes, but mitochondrial DNA is inherited solely from the mother.
The human genome has about 3 billion different nucleotides, coding about 20,000 genes on 23 chromosomes. A gene is a DNA sequence that has some effect on the phenotype of an organism. In prokaryotes, the genomic DNA is typically in the form of one or more small rings called plasmids.
DNA Replication
![[4]](https://ds055uzetaobb.cloudfront.net/brioche/uploads/APYCto4GKu-dna_bubbles-1.png?width=1200) [4]
The complexity of DNA's molecular structure ensures it can self-replicate and pass its code to new cells. Many enzymes and proteins are involved in replicating the DNA strand to ensure the process is fast and efficient enough to serve the organism's needs.
[4]
The complexity of DNA's molecular structure ensures it can self-replicate and pass its code to new cells. Many enzymes and proteins are involved in replicating the DNA strand to ensure the process is fast and efficient enough to serve the organism's needs.
The two DNA strands are antiparallel, meaning they are oriented opposite directions from one another. When new strands of DNA are elongated, nucleotides are always added to the 3' end, never to the 5' end.
Replication starts at many points along the DNA strand, forming bubbles where the helix is partially unwound. At the end of each bubble is a replication fork, where the enzyme DNA polymerase III attaches and elongates the daughter strand of DNA. On one side, the replication of the daughter strand proceeds in a single piece in the 5' to 3' direction. This is called the leading strand. On the other side, the parent strand is going in the 5' to 3' direction. Since the daughter strand must also elongate in the 5' to 3' direction, DNA polymerase III attaches at the end of the replication bubble and works backward along the template strand. Since there is more torsion where the bubble is narrower, the lagging strand is generated in shorter chunks called Okazaki fragments (named for the Japanese scientist who discovered them). However, DNA polymerase III requires a free 3'-OH in order to start synthesizing a chain, so primase synthesizes RNA primers on the lagging strand. After all the fragments are synthesized, the primers are removed by RNase H and the enzyme DNA polymerase I fills in the gaps. DNA ligase later bonds the fragments together. To be clear, DNA polymerase I contains several subunits; 5'-3' exonuclease activity for removing RNA primers, 3'-5' exonuclease activity for proofreading, and 5'-3' polymerase activity. This replication process is semi-conservative, as each of the resulting DNA molecules contains one parent strand and one daughter strand. By comparison, there are two other theoretical modes of DNA replication that are unlikely to naturally occur: conservative replication, where after replication, one DNA molecule is composed completely of daughter strands and the other copy is composed completely of parent strands, and dispersive replication, where each strand of DNA is a mixture of new and old DNA after replication.
![[5]](https://ds055uzetaobb.cloudfront.net/brioche/uploads/18fEdvEmRf-dnareplication.png?width=1200) [5]
[5]
 A bacterial cell with adequate food can replicate in under an hour. In this time, everything in the cell must be copied, including its genome (i.e. the DNA). A copy of the DNA is made by molecular machines called DNA polymerase, which can copy 600 base pairs per second. If the genome of the strain B. acterium is \(4.5\times10^6\) base pairs long, and there are 6 molecules of DNA polymerase in the cell, how long (in seconds) would it take to copy the entire genome?
A bacterial cell with adequate food can replicate in under an hour. In this time, everything in the cell must be copied, including its genome (i.e. the DNA). A copy of the DNA is made by molecular machines called DNA polymerase, which can copy 600 base pairs per second. If the genome of the strain B. acterium is \(4.5\times10^6\) base pairs long, and there are 6 molecules of DNA polymerase in the cell, how long (in seconds) would it take to copy the entire genome?
Common Genetic Problems
Overall, DNA replication is very accurate. Additionally, the redundancy of the genetic code allows for silent mutations (wrong codon sequence but same amino acid). However, errors do occur, and can lead to a variety of abnormalities in the affected offspring.
Mutations are any change to the order of base pairs in the DNA. If transcription proceeds incorrectly, bases may be substituted for one another, added, or deleted. Changes to a single base pair are called point mutations. These changes may alter the amino acid chain assembled during translation, which will in turn affect the overall structure of the protein. The protein may be dysfunctional as a result. Mutations are not always harmful. The protein may fold in a manner that makes it function even better, giving the organism a selective advantage. If this is the case, the organism may have a better chance of reproductive success and may pass that mutation to multiple offspring.
![Blood smear showing both normal red blood cells and sickle cells[6]](https://ds055uzetaobb.cloudfront.net/brioche/uploads/avf7RtGeFT-sickle-cell_smear_2015-09-10.jpg?width=1200) Blood smear showing both normal red blood cells and sickle cells[6]
Blood smear showing both normal red blood cells and sickle cells[6]
Mutations cause variation, and the environment determines whether that difference is an advantage or a disadvantage. Sickle-cell anemia is caused by a single base-pair substitution in the DNA, which in turn causes one amino acid to be different in the gene that makes red blood cells. Instead of being round, the blood cells are shaped more like a crescent. People who carry one copy of this gene with this mutation are less likely to get malaria, so the mutation is common in areas like Africa, India, and the Mediterranean. However, the sickle-shaped blood cells do not carry oxygen as efficiently as their donut-shaped counterparts, so people who carry two copies of the gene are still less likely to get malaria, but they cannot circulate oxygen through their body as efficiently, which can lead to severe pain and organ damage. One copy of the mutation can be advantageous to a person's health, while two copies may be disastrous.
Chromosomal breakage results in the DNA losing its helical structure. Exposure to UV light, X rays, and certain chemicals can cause breakage. A physical or chemical substance that changes the structure of DNA is referred to as a mutagen. Breakage can also occur spontaneously. If both strands of DNA are affected, the information lost cannot be recovered.
Nondisjunction is the failure of chromosomes to separate correctly during the production of gametes. The resulting offspring may have only one copy of a chromosome (monosomy), or it may have three copies of the chromosome (trisomy). Down's syndrome is an example of trisomy in humans. It is caused by an extra copy of chromosome 21. Most nondisjunction is lethal in humans and result in a miscarriage early in pregnancy.
![Human genome with a trisomy on chromosome 21 [7]](https://ds055uzetaobb.cloudfront.net/brioche/uploads/41i8jYakne-21_trisomy_-_down_syndrome.png?width=1200) Human genome with a trisomy on chromosome 21 [7]
Human genome with a trisomy on chromosome 21 [7]
References
[1] Image modified from https://commons.wikimedia.org/wiki/File:Componentes_nucleotidos.png under Creative Commons licensing for reuse and modification.
[2] Image from https://commons.wikimedia.org/wiki/File:Nucleotide.gif under Creative Commons licensing for reuse and modification.
[3] Image from https://commons.wikimedia.org/wiki/File:A-B-Z-DNASideView.png under Creative Commons licensing for reuse and modification.
[4] Image from https://commons.wikimedia.org/wiki/File:DNA_bubbles.png under Creative Commons licensing for reuse and modification.
[5] Image from https://upload.wikimedia.org/wikipedia/commons/9/93/Dnareplication.png under Creative Commons licensing for reuse and modification.
[6] Image from https://commons.wikimedia.org/wiki/File:Sickle-cellsmear2015-09-10.jpg under Creative Commons licensing for reuse and modification.
[7] Image from https://commons.wikimedia.org/wiki/File:21trisomy-Downsyndrome.png under Creative Commons licensing for reuse and modification.