Mutation and DNA repair
Mutation is a random process where DNA is copied incorrectly, and the order of base pairs in the daughter strand is different from the order in the parent strand. Even a single difference in base pairs can lead to a change in the structure and function of the product protein. DNA is constantly changing through the process of mutation.
DNA mutations range from harmless to deadly. Many inherited diseases and disorders are caused by changes to a single gene. Examples include sickle-cell-anemia, cystic fibrosis, phenylketonuria, Tay-Sachs disease, and colorblindness.
When examining completed DNA molecules, errors in DNA replication appear rare; they occur in approximately 1 of every 10 billion nucleotides copied. However, errors between the template strand and the single nucleotides being added to the daughter strand are far more common: 1 in 100,000. The majority of these errors are proofread and corrected by the enzyme DNA polymerase during the elongation of the daughter strand.
While it is usually assumed that mutations are harmful, because they are most commonly talked about in the context of diseases, mutations are not inherently bad. Most of them aren't even detectable. Others, such as blue eyes or a taller stature, may be considered desirable. Whether a mutation is helpful or harmful depends primarily on the environment the organism inhabits, and how the difference changes its chance of surviving.
 Public Domain Image
Public Domain Image
Types of Mutations
Any time DNA is replicated or divided, there is an opportunity for mutation.
Point mutations occur when there is a chemical change to a single base pair.
 public domain image
public domain image
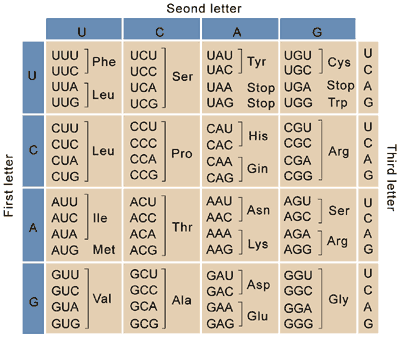
Substitutions occur when one nucleotide is replaced with a different nucleotide. Since there is redundancy in the genetic code (multiple base pair triplets can code for the same amino acid, see table at right), a base pair substitution may not affect which nucleotide is added to the DNA strand. These substitutions are called silent mutations. For example, a section of DNA that has mutated such that its transcribed mRNA strand reads as GUU rather than GUA would still code for the amino acid valine during protein synthesis. The structure of the DNA molecule is affected, but the structure of the resulting protein is not.
Missense errors occur when the mutated DNA can still code for an amino acid, but not the correct amino acid. If the rest of the genetic code is intact, the mutated DNA may still produce a functional protein, albeit with a different structure and properties.
Nonsense errors occur when the mutated DNA produces a stop codon too early, terminating polypeptide synthesis. Usually, these shortened polypeptide chains cannot fold into functional proteins.
Insertions occur when an extra nucleotide is added to the DNA strand. Deletions occur when a nucleotide is removed from the DNA strand. Both insertions and deletions are referred to as frameshift mutations, because all the nucleotides downstream are grouped incorrectly.
Mutagens
A mutagen is a physical or chemical substance that disrupts DNA, causing a permanent change in the nucleotide sequence.
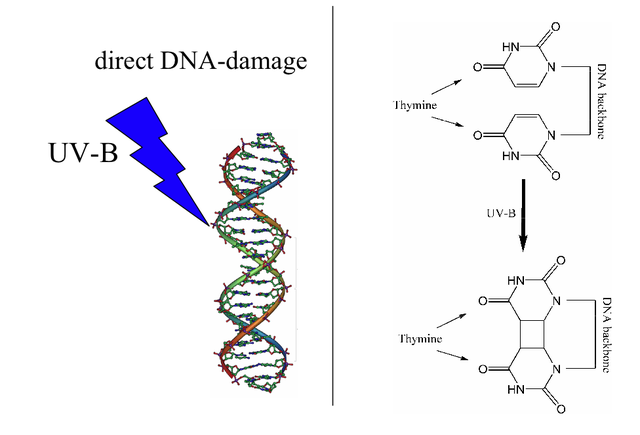
Ultraviolet radiation is a common physical mutagen. It causes neighboring thymines to form dimers, changing the shape of the double helix. Sunburns occur when too many of these dimers form, and they cannot all be repaired, and the cells die instead. Nucleotide sequence errors are sometimes introduced into the DNA sequence as the damage is repaired, and an error may result in unchecked cell growth, leading to skin cancer.
 public domain image
public domain image
Methods of DNA Repair
When examining completed DNA molecules, errors in DNA replication appear rare; they occur in approximately 1 of every 10 billion nucleotides copied. However, errors between the template strand and the single nucleotides being added to the daughter strand are far more common: 1 in 100,000.
Mismatched nucleotides that are not detected by DNA polymerase or that result from damage after the strand has been synthesized are corrected by special enzymes in a process called mismatch repair.
Nucleotide excision repair takes advantage of DNA base-pairing to correct problem segments. The damaged section is removed by the enzyme nuclease, and the gaps are filled in by the polymerase and ligase enzymes, following the template of the undamaged strand.