Shortest Path Algorithms
Shortest path algorithms are a family of algorithms designed to solve the shortest path problem. The shortest path problem is something most people have some intuitive familiarity with: given two points, A and B, what is the shortest path between them? In computer science, however, the shortest path problem can take different forms and so different algorithms are needed to be able to solve them all.
For simplicity and generality, shortest path algorithms typically operate on some input graph, \(G\). This graph is made up of a set of vertices, \(V\), and edges, \(E\), that connect them. If the edges have weights, the graph is called a weighted graph. Sometimes these edges are bidirectional and the graph is called undirected. Sometimes there can be even be cycles in the graph. Each of these subtle differences are what makes one algorithm work better than another for certain graph type. An example of a graph is shown below.
 An undirected, weighted graph
An undirected, weighted graph
There are also different types of shortest path algorithms. Maybe you need to find the shortest path between point A and B, but maybe you need to shortest path between point A and all other points in the graph.
Shortest path algorithms have many applications. As noted earlier, mapping software like Google or Apple maps makes use of shortest path algorithms. They are also important for road network, operations, and logistics research. Shortest path algorithms are also very important for computer networks, like the Internet.
Any software that helps you choose a route uses some form of a shortest path algorithm. Google Maps, for instance, has you put in a starting point and an ending point and will solve the shortest path problem for you.
Contents
Types of Graphs
There are many variants of graphs. The first property is the directionality of its edges. Edges can either be unidirectional or bidirectional. If they are unidirectional, the graph is called a directed graph. If they are bidirectional (meaning they go both ways), the graph is called a undirected graph. In the case where some edges are directed and others are not, the bidirectional edges should be swapped out for 2 directed edges that fulfill the same functionality. That graph is now fully directed.
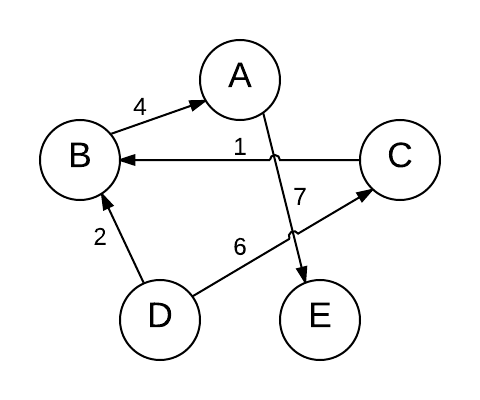 The same graph as above, but directed
The same graph as above, but directed
The second property of a graph has to do with the weights of the edges. Edges can have no weight, and in that case the graph is called unweighted. If edges do have weights, the graph is said to be weighted. There is an extra caveat here: graphs can be allowed to have negative weight edges. The inclusion of negative weight edges prohibits the use of some shortest path algorithms.
The third property of graphs that affects what algorithms can be used is the existence of cycles. A cycle is defined as any path \(p\) through a graph, \(G\), that visits that same vertex, \(v\), more than once. So, if a graph has any path that has a cycle in it, that graph is said to be cyclic. Acyclic graphs, graphs that have no cycles, allow more freedom in the use of algorithms.
 Cyclic graph with cyclic path A -> E -> D -> B -> A
Cyclic graph with cyclic path A -> E -> D -> B -> A
Types of Shortest Path Algorithms
There are two main types of shortest path algorithms, single-source and all-pairs. Both types have algorithms that perform best in their own way. All-pairs algorithms take longer to run because of the added complexity. All shortest path algorithms return values that can be used to find the shortest path, even if those return values vary in type or form from algorithm to algorithm.
Single-source
Single-source shortest path algorithms operate under the following principle:
Given a graph \(G\), with vertices \(V\), edges \(E\) with weight function \(w(u, v) = w_{u, v}\), and a single source vertex, \(s\), return the shortest paths from \(s\) to all other vertices in \(V\).
If the goal of the algorithm is to find the shortest path between only two given vertices, \(s\) and \(t\), then the algorithm can simply be stopped when that shortest path is found. Because there is no way to decide which vertices to "finish" first, all algorithms that solve for the shortest path between two given vertices have the same worst-case asymptotic complexity as single-source shortest path algorithms.
This paradigm also works for the single-destination shortest path problem. By reversing all of the edges in a graph, the single-destination problem can be reduced to the single-source problem. So, given a destination vertex, \(t\), this algorithm will find the shortest paths starting at all other vertices and ending at \(t\).
All-pairs
All-pairs shortest path algorithms follow this definition:
Given a graph \(G\), with vertices \(V\), edges \(E\) with weight function \(w(u, v) = w_{u, v}\) return the shortest path from \(u\) to \(v\) for all \((u, v)\) in \(V\).
The most common algorithm for the all-pairs problem is the floyd-warshall algorithm. This algorithm returns a matrix of values \(M\), where each cell \(M_{i, j}\) is the distance of the shortest path from vertex \(i\) to vertex \(j\). Path reconstruction is possible to find the actual path taken to achieve that shortest path, but it is not part of the fundamental algorithm.
Algorithms
The Bellman-Ford algorithm solves the single-source problem in the general case, where edges can have negative weights and the graph is directed. If the graph is undirected, it will have to modified by including two edges in each direction to make it directed.
Bellman-Ford has the property that it can detect negative weight cycles reachable from the source, which would mean that no shortest path exists. If a negative weight cycle existed, a path could run infinitely on that cycle, decreasing the path cost to \(- \infty\).
If there is no negative weight cycle, then Bellman-Ford returns the weight of the shortest path along with the path itself.
Dijkstra's algorithm makes use of breadth-first search (which is not a single source shortest path algorithm) to solve the single-source problem. It does place one constraint on the graph: there can be no negative weight edges. However, for this one constraint, Dijkstra greatly improves on the runtime of Bellman-Ford.
Dijkstra's algorithm is also sometimes used to solve the all-pairs shortest path problem by simply running it on all vertices in \(V\). Again, this requires all edge weights to be positive.
Topological Sort
For graphs that are directed acyclic graphs (DAGs), a very useful tool emerges for finding shortest paths. By performing a topological sort on the vertices in the graph, the shortest path problem becomes solvable in linear time.
A topological sort is an ordering all of the vertices such that for each edge \((u, v)\) in \(E\), \(u\) comes before \(v\) in the ordering. In a DAG, shortest paths are always well defined because even if there are negative weight edges, there can be no negative weight cycles.
The Floyd-Warshall algorithm solves the all-pairs shortest path problem. It uses a dynamic programming approach to do so. Negative edge weight may be present for Floyd-Warshall.
Floyd-Warshall takes advantage of the following observation: the shortest path from A to C is either the shortest path from A to B plus the shortest path from B to C or it's the shortest path from A to C that's already been found. This may seem trivial, but it's what allows Floyd-Warshall to build shortest paths from smaller shortest paths, in the classic dynamic programming way.
While Floyd-Warshall works well for dense graphs (meaning many edges), Johnson's algorithm works best for sparse graphs (meaning few edges). In sparse graphs, Johnson's algorithm has a lower asymptotic running time compared to Floyd-Warshall.
Johnson's algorithm takes advantage of the concept of reweighting, and it uses Dijkstra's algorithm on many vertices to find the shortest path once it has finished reweighting the edges.

Comparison of Algorithms
The runtimes of the shortest path algorithms are listed below.
See also: big O notation.
| Algorithm | Runtime |
| Bellman-Ford | \(O(|V| \cdot |E|)\) |
| Dijkstra's (with list) | \(O(|V|^2)\) |
| Topological Sort | \(O(|V| + |E|)\) |
| Floyd-Warshall | \(O(|V|^3)\) |
| Johnson's | *\(O(|E| \cdot |V| + |V|^2 \cdot \log_2(|V|))\) |
*This runtime assumes that the implementation uses fibonacci heaps.
Oftentimes, the question of which algorithm to use is not left up to the individual; it is merely a function of what graph is being operated upon and which shortest path problem is being solved.
For graphs with negative weight edges, the single source shortest path problem needs Bellman-Ford to succeed. For dense graphs and the all-pairs problem, Floyd-Warshall should be used.
However, there are some subtle differences. For sparse graphs and the all-pairs problem, it might be obvious to use Johnson's algorithm. However, if there are no negative edge weights, then it is actually better to use Dijkstra's algorithm with binary heaps in the implementation. Running Dijsktra's from each vertex will yield a better result.
From a space complexity perspective, many of these algorithms are the same. In their most fundemental form, for example, Bellman-Ford and Dijkstra are the exact same because they use the same representation of a graph. However, when these algorithms are sped up using advanced data structures like fibonacci or binary heaps, the space required to perform the algorithm increases. As is common with algorithms, space is often traded for speed.
Improvements
These algorithms have been improved upon over time. Dijkstra's algorithm, for example, was initally implemented using a list, and had a runtime of \(O(|V|^2)\). However, when a binary heap is used, a runtime of \(O((|E|+|V|) \cdot \log_2(|V|))\) has been achieved. When a fibonacci heap is used, one implementation can achieve \(O(|E| + |V| \cdot \log_2(|V|))\) while another can do \(O(|E| \cdot \log_2(\log_2(|C|)))\) where \(|C|\) is a bounded constant for edge weight.
Bellman-Ford has been implemented in \(O(|V|^2 \cdot \log_2(|V|))\). This implementation can be efficient if used on the right kind of graph (sparse).