Classification Problems
Classification is a central topic in machine learning that has to do with teaching machines how to group together data by particular criteria. Classification is the process where computers group data together based on predetermined characteristics — this is called supervised learning. There is an unsupervised version of classification, called clustering where computers find shared characteristics by which to group data when categories are not specified.
A common example of classification comes with detecting spam emails. To write a program to filter out spam emails, a computer programmer can train a machine learning algorithm with a set of spam-like emails labelled as spam and regular emails labelled as not-spam. The idea is to make an algorithm that can learn characteristics of spam emails from this training set so that it can filter out spam emails when it encounters new emails.
Classification is an important tool in today’s world, where big data is used to make all kinds of decisions in government, economics, medicine, and more. Researchers have access to huge amounts of data, and classification is one tool that helps them to make sense of the data and find patterns.
While classification in machine learning requires the use of (sometimes) complex algorithms, classification is something that humans do naturally everyday. Classification is simply grouping things together according to similar features and attributes. When you go to a grocery store, you can fairly accurately group the foods by food group (grains, fruit, vegetables, meat, etc.) In machine learning, classification is all about teaching computers to do the same.
Intuition
Here are a few examples of situations where classification is useful:
Classifying Images
Let’s say you are trying to write a machine learning program that will be able to detect cancerous tumors in lungs. It takes in images of lung x-rays as input and determines if there is a tumor. If there is a tumor, we’d like the computer to output “yes” and if there is not a tumor, we’d like the computer to output “no.” We’d like the computer to output the correct answer as much as possible.Speech TaggingSay the training set for this algorithm consists of several images of x-rays, half of the images contain tumors and are labelled “yes” and the other half do not contain tumors and are labelled “no.”
If the algorithm learns how to identify tumors with high accuracy, you can see why this might be a useful tool in a medical setting — a computer could save doctors time by analyzing x-ray images quickly.
Let’s say there are linguistics researchers studying grammar structures in languages. They have a bunch of text files of transcribed speeches that they want to analyze. They want to teach a computer to recognize parts of speech, such as adjectives, subject, and verbs, in the sentences.
Music Identification
Let’s say you are writing a program that recommends new music to a user based on their music preferences. The user selects from a list of songs the songs that he or she likes and the program should show him or her new songs that they are likely to enjoy.
In this case, what is the input training data? What are the labels?
The input data would be the songs that the user selected that they liked, this could be labelled as “like” and the songs that the user did not select from the list are labelled as “dislike.”
Quality Control
Say you work in a computer processor factory. As the processors are being prepared to be packaged and shipped, you must conduct a quality check to make sure that none of the processors are damaged. Describe how you might get a computer to do this job for you using machine learning and classification.
You could connect a computer to a camera that photographs each processor before it is shipped. The computer will run an algorithm that classifies the processor as damaged or not damaged. The training set you could use to teach this algorithm to determine which processors are damaged would be images of defective processors and images of functional processors.
Classification Algorithms
Choosing the right classification algorithm is very important. An algorithm that performs classification is called a classifier. A classifier algorithm should be fast, accurate, and sometimes, minimize the amount of training data that it needs. Generally, the more parameters a set of data has, the larger the training set for an algorithm must be. Different classification algorithms basically have different ways of learning patterns from examples. [1]
More formally, classification algorithms map an observation \(v\) to a concept/class/label \(\omega\).
Many times, classification algorithms will take in data in the form of a feature vector which is basically a vector containing numeric descriptions of various features related to each data object. For example, if the algorithm deals with sorting images of animals into various classes (based on what type of animal they are, for example), the feature vector might include information about the pixels, colors in the image, etc.
Here are some common classification algorithms and techniques:
Linear Regression
A common and simple method for classification is linear regression.
Linear regression is a technique used to model the relationships between observed variables. The idea behind simple linear regression is to "fit" the observations of two variables into a linear relationship between them. Graphically, the task is to draw the line that is "best-fitting" or "closest" to the points \( (x_i,y_i),\) where \( x_i\) and \(y_i\) are observations of the two variables which are expected to depend linearly on each other.
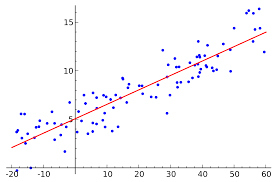 The best-fitting linear relationship between the variables \(x\) and \(y\). [2]
The best-fitting linear relationship between the variables \(x\) and \(y\). [2]
Which of these lines, H1, H2, and H3, represents the worst classifier algorithm? (The classifier algorithms identify and label data and place them on one side of the line or the other according to the results).
H3 and H2 have no error in this graph — all of the solid circles are to one side and all of the hollow circles are to the other side of the lines. H1, on the other hand, groups solid circles with the hollow circles, this is a poor classifier.

Perceptrons
A perceptron is an algorithm used to produce a binary classifier. That is, the algorithm takes binary classified input data, along with their classification and outputs a line that attempts to separate data of one class from data of the other: data points on one side of the line are of one class and data points on the other side are of the other. Binary classified data is data where the label is one thing or another, like "yes" or "no"; 1 or 0; etc.
The perceptron algorithm returns values of \(w_0, w_1, ..., w_k\) and \(b\) such that data points on one side of the line are of one class and data points on the other side are of the other. Mathematically, the values of \(\boldsymbol{w}\) and \(b\) are used by the binary classifier in the following way. If \(\boldsymbol{w} \cdot \boldsymbol{x} + b > 0\), the classifier returns 1; otherwise, it returns 0. Note that 1 represents membership of one class and 0 represents membership of the other. This can be seen more clearly with the AND operator, replicated below for convenience.
 The AND operation between two numbers. A red dot represents one class (\(x_1\) AND \(x_2 = 0\)) and a blue dot represents the other class (\(x_1\) AND \(x_2 = 1\)). The line is the result of the perceptron algorithm, which separates all data points of one class from those of the other.
The AND operation between two numbers. A red dot represents one class (\(x_1\) AND \(x_2 = 0\)) and a blue dot represents the other class (\(x_1\) AND \(x_2 = 1\)). The line is the result of the perceptron algorithm, which separates all data points of one class from those of the other.
The perceptron algorithm is one of the most commonly used machine learning algorithms for binary classification. Some machine learning tasks that use the perceptron include determining gender, low vs high risk for diseases, and virus detection.
Naive Bayes Classifier
Naive Bayes classifiers are probabilistic classifiers with strong independence assumptions between features. Unlike many other classifiers which assume that, for a given class, there will be some correlation between features, naive Bayes explicitly models the features as conditionally independent given the class.
Because of the independence assumption, naive Bayes classifiers are highly scalable and can quickly learn to use high dimensional (many parameters) features with limited training data. This is useful for many real world datasets where the amount of data is small in comparison with the number of features for each individual piece of data, such as speech, text, and image data.
Decision Trees
Another way to do a classification is to use a decision tree.
Other types of classification algorithms include support vector machines (SVMs), Bayesian, and logistic regression.Say you have the following training data set of basketball players that includes information about what color jersey they have, which position they play, and whether or not they are injured. The training set is labelled according to whether or not a player will be able to play for Team A.
Person Jersey Color Offense or Defense Injured? Will they play for Team A? John Blue Offense No Yes Steve Red Offense No No Sarah Blue Defense No Yes Rachel Blue Offense Yes No Richard Red Defense No No Alex Red Defense Yes No Lauren Blue Offense No Yes Carol Blue Defense No Yes What is the rule for whether or not a player may play for Team A?
They must have a blue jersey and not be injured.To use a decision tree to classify this data, select a rule to start the tree.
Here we will use “jersey color” as the root node.

Next, we will include a node that will distinguish between injured and uninjured players.

Use of Statistics In Input Data
Classification algorithms often include statistics data.
Let's say a company is trying to write software that will take in as input the full text of a book. From the frequency of certain words, the program will determine which genre the book belongs to. Perhaps if the word "detective" appears very frequently, the program will label the book as a "mystery." If the book contains the word "magic" or "wizard" many times, perhaps the software should label the book as "fantasy." And so forth. (In this example, the language of the books is English).ErrorLet's say that the computer program goes through each book and keeps track of the number of times each word occurs. The algorithm might find that across all genres, the words "the," "is," "and,", "I," and other very common English words occur with about the same frequency. Classifying the novels based on these word frequencies would probably not be very helpful. However, if the algorithm notices that a particular subset of words tend to occur more often in science-fiction novels and fantasy novels than in mystery novels or non-fiction novels, the algorithm can use this information to sort future book instances.
In the basketball team example above, the rules for determining if a player would play for Team A were fairly straightforward with just two binary data points to consider. In book genre example, a historical-fiction novel might contain the word "detective" many times if its topic has to do with a famous unsolved crime. It is possible that the machine learning algorithm would classify this novel as a mystery book. This is called error. Many times, error can be reduced by feeding the algorithm more training examples. However, eliminating error completely is very difficult to do, so in general, a good classifier algorithm will have as low an error rate as possible.
Conclusion
Classification, and its unsupervised learning counterpart, clustering, are central ideas behind many other techniques and topics in machine learning. Being able to classify and recognize certain kinds of data allows computer scientists to expand on knowledge and applications in other machine learning fields such as computer vision, natural language processing, deep learning, building predictive economic, market, and weather models, and more.
See Also
References
- Schurmann, J. (1996). Pattern Classification. John Wiley & Sons Inc..
- Sewaqu, . Linear regression. Retrieved November 5, 2010, from https://en.wikipedia.org/wiki/Least_squares#/media/File:Linear_regression.svg
- , Z. File:Svm separating hyperplanes (SVG).svg. Retrieved July 18, 2016, from https://en.wikipedia.org/wiki/File:Svm_separating_hyperplanes_(SVG).svg
{kind=link}
.svg){kind=link}