Randomized Algorithms
A randomized algorithm is a technique that uses a source of randomness as part of its logic. It is typically used to reduce either the running time, or time complexity; or the memory used, or space complexity, in a standard algorithm. The algorithm works by generating a random number, \(r\), within a specified range of numbers, and making decisions based on \(r\)'s value.
A randomized algorithm could help in a situation of doubt by flipping a coin or a drawing a card from a deck in order to make a decision. Similarly, this kind of algorithm could help speed up a brute force process by randomly sampling the input in order to obtain a solution that may not be totally optimal, but will be good enough for the specified purposes.
A superintendent is attempting to score a high school based on several metrics, and she wants to do so from information gathered by confidentially interviewing students. However, the superintendent has to do this with all the schools in the district, so interviewing every single student would take a time she cannot afford. What should she do?
The superintendent should employ a randomized algorithm, where, without knowing any of the kids, she’d select a few at random and interview them, hoping that she gets a wide variety of students. This technique is more commonly known as random sampling, which is a kind of randomized algorithm. Of course, she knows that there are diminishing returns from each additional interview, and should stop when the quantity of data collected measures what she was trying to measure to an acceptable degree of accuracy. The way that the superintendent is determining the score of the school can be thought of as a randomized algorithm.
Contents
Definitions of a Randomized Algorithm
Randomized algorithms are used when presented with a time or memory constraint, and an average case solution is an acceptable output. Due to the potential erroneous output of the algorithm, an algorithm known as amplification is used in order to boost the probability of correctness by sacrificing runtime. Amplification works by repeating the randomized algorithm several times with different random subsamples of the input, and comparing their results. It is common for randomized algorithms to amplify just parts of the process, as too much amplification may increase the running time beyond the given constraints.
Randomized algorithms are usually designed in one of two common forms: as a Las Vegas or as a Monte Carlo algorithm. A Las Vegas algorithm runs within a specified amount of time. If it finds a solution within that timeframe, the solution will be exactly correct; however, it is possible that it runs out of time and does not find any solutions. On the other hand, a Monte Carlo algorithm is a probabilistic algorithm which, depending on the input, has a slight probability of producing an incorrect result or failing to produce a result altogether.
Practically speaking, computers cannot generate completely random numbers, so randomized algorithms in computer science are approximated using a pseudorandom number generator in place of a true source of random number, such as the drawing of a card.
Monte Carlo Algorithms
Intuitive Explanation
The game, Wheel of Fortune, can be played using a Monte Carlo randomized algorithm. Instead of mindfully choosing letters, a player (or computer) picks randomly letters to obtain a solution, as shown in the image below. The more letters a player reveals, the more confident a player becomes in their solution. However, if a player does not guess quickly, the chance that other players will guess the solution also increases. Therefore, a Monte Carlo algorithm is given a deterministic amount of time, in which it must come up with a "guess" based on the information revealed; the best solution it can come up with. This allows for the possibility of being wrong, maybe even a large probability of being wrong if the Monte Carlo algorithm did not have sufficient time to reveal enough useful letters. But providing it with a time limit controls the amount of time the algorithm will take, thereby decreasing the risk of another player guessing and getting the prize. It is important to note, however, that this game differs from a standard Monte Carlo algorithm as the game has one correct solution, whereas for a Monte Carlo algorithm, the 'good enough' solution is an acceptable output.
 Wheel of Fortune Board. When should you stop revealing letters and guess the word?
Wheel of Fortune Board. When should you stop revealing letters and guess the word?
The term for this algorithm, Monte Carlo, was coined by mathematicians Nicholas Metropolis, Stanislaw Ulam, and John von Neumann, working on the Manhattan Project, around the 1940s. The name was found in a research paper published in 1949, attributed by some sources to the fact that Ulam’s uncle made a yearly trip to gamble at Monte Carlo, in Monaco. [1]
Technical Example: Approximating \(\pi\)
A classic example of a more technical Monte Carlo algorithm lies in the solution to approximating pi, \(\pi\), the ratio of a circle's circumference to its diameter. This approximation problem is so common that it's actually asked in job interviews for programmer positions at big banks and other mathematically rigorous companies.
Imagine you're blind and someone asks you to find the shape of an object. Intuitively, the solution would be to touch the object in as many places as possible until a familiar object come to mind, at which point you make a guess. The same strategy is applied when approximating \(\pi\).
Start with a Cartesian plane (x,y coordinates) with an x-axis from \(-1\) to \(1\), and a y-axis from \(-1\) to \(1\). This will be a \(2\ \times\ 2\) box. Then generate many random points on this grid. Count the number of points, C, that fall within a distance of \(1\) from the origin \((0, 0)\), and the number of points, T, that don't. For instance, \((0.5,0)\) is less than \(1\) from the origin, but \((-0.9, 0.9)\) is \(\sqrt(1.62)\) from the origin, by the pythagorean theorem.
We can now approximate pi by knowing that the ratio of the area of a circle to the area of the rectangular bounds should be equal to the ratio of points inside the circle to those outside the circle; namely,
\(\frac{\pi r^2}{4r^2} \approx (\frac{C}{T}\))
This leads to the conclusion that as more random samples are obtained, the approximation to \(\pi\) is improved, as shown below.
Monte Carlo Approximation of \(\pi\) [2]
Las Vegas Algorithms
Intuition
A Las Vegas algorithm is a randomized algorithm that always produces a correct result, or simply doesn’t find one, yet it cannot not guarantee a time constraint; the time complexity varies on the input. It does, however, guarantee an upper bound in the worst-case scenario.
Las Vegas algorithms occur almost every time people look something up. Think of a Las Vegas algorithm as a task that when the solution is found, it has full confidence that it is the correct solution, yet the path to get there can be murky. As an extremely generalized and simplified example, a Las Vegas algorithm could be thought of as the strategy used by a user who searches for something online. Since searching every single website online is extremely inefficient, the user will generally use a search engine to get started. The user will then surf the web until a website is found which contains exactly what the user is looking for. Since clicking through links is a decently randomized process, assuming the user does not know exactly what’s contained on the website at the other end of the, the time complexity ranges from getting lucky and reaching the target website on the first link, to being unlucky and spending countless hours to no avail. What makes this a Las Vegas algorithm is that the user knows exactly what she is looking for, so once the website is found, there is no probability of error. Similarly, if the user’s allotted time to surf the web is exceeded, she will terminate the process knowing that the solution was not found.
The term for this algorithm, Las Vegas, is attributed to mathematician Laszlo Babai, who coined it in 1979 simply as a parallel to the much older Monte Carlo algorithm, as both are major world gambling centers. However, the gambling styles of the two have nothing to do with the styles of the algorithms, as it cannot be said that gambling in Las Vegas always gives a correct, or even positive, turnout. [3]
Randomized Quicksort
A common Las Vegas randomized algorithm is quicksort, a sorting algorithm that sorts elements in place, using no extra memory. Since this is a comparison based algorithm, the worst case scenario will occur when performing pairwise comparison, taking \(O(n^2)\), where the time taken grows as a square of the number of digits to be sorted grows. However, through randomization, the runtime of this algorithm can be reduced up to \(O(n\ log(n))\).
Quicksort applies a divide-and-conquer paradigm in order to sort an array of numbers, \(A\). It works in three steps: it first picks a pivot element, \(A[q]\), using a random number generator (hence a randomized algorithm); then rearranges the array into two subarrays \(A[p \dots q-1]\) and \(A[q+1 \dots r]\), where the elements in the first and second arrays are smaller and greater than \(A[q]\), respectively.
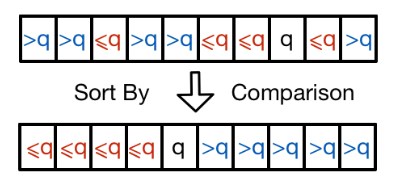 Array A sorted and partitioned around pivot element q.
Array A sorted and partitioned around pivot element q.
The algorithm then recursively applies the above steps of quicksort on the two independent arrays, thereby outputting a fully sorted array.
Pseudocode
1 2 3 4 5 6 7 8 9 10 11 | |
In the worst case scenario, this algorithm takes O(n^2) time to sort \(n\) digits in case the pivot element chosen at random is the first or last element in the array.
The following is a time complexity analysis for the worst-case scenario of quicksort. Since each insertion and removal takes \(O(1)\) time, and partitioning takes \(O(n)\) time, as every item must be iterated over to create both subarrays, if the smallest or the largest elements in the array are picked, the partition will result in two arrays: one of size 0, since there will be no items at one extreme of the array, and an array of size \(O(n-1)\); excluding the pivot element chosen. Therefore, the runtime analysis is the following:
\(T(n) = T(0) + T(n-1) + \Theta(n)\)
\(T(n) = \Theta(1) + T(n-1) + \Theta(n)\)
\(T(n) = T(n-1) + \Theta(n)\)
\(T(n) = \Theta(n^2)\)
Where the last step follows from the arithmetic series.
Now, using randomized quicksort, where the pivot is chosen at random, and neither the smallest or the largest number in the array are selected, the expected runtime is \(O(n\ log(n)) \).
If luck is on the algorithm’s side and middle valued elements are picked each time, the array will constantly be partitioned in half, obtaining the following time complexity:
\(T(n) \leq 2*T(\frac{n}{2}) + \Theta(n)\)
\(T(n) = \Theta(n log(n))\)
However, the probability that this happens is one out of \(n\) numbers, which is extremely small. However, what if we get a 10%-90% split instead of a 50%, 50%, as shown above? The algorithm still works! This is because the depth of the recursion tree will still be \(O(log (n) )\), and it takes \(O(n)\) to perform one level of the recursion tree. Therefore, randomizing quicksort gives a great advantage to sorting an array of numbers.
Atlantic City Algorithms
Monte Carlo algorithms are always fast and probably correct, whereas Las Vegas algorithms are sometimes fast but always correct. There is a type of algorithm that lies right in the middle of these two, and it is called the Atlantic City algorithm. This type of algorithm meets the other two halfway: it is almost always fast, and almost always correct. However, designing these algorithms is an extremely complex process, so very few of them are in existence.
Computational Complexity
Randomized algorithms have a complexity class of their own, since they operate under Probabilistic Turing Machines. The most basic probabilistic complexity class is called RP, randomized polynomial time algorithms, which encompass problems with an efficient randomized algorithm, taking polynomial time, and recognizes bad solutions with absolute certainty, and correct solutions with probability of at least ½.
Amplification can be used with RP algorithms in order to increase the probability that the correct answer is recognized. Since said recognition occurs with probability ½, the algorithm can be repeated \(n\) times in order to obtain the correct solution with probability 1- \((\frac{1}{2})^n\) times. Therefore, if an RP algorithm is executed 100 times, the chance of obtaining a wrong answer every time is lower than the chance that cosmic rays corrupted the memory of the computer running the algorithm! This makes RP algorithms extremely practical. [4]
The complement of RP class is called co-RP, implying that correct solutions are accepted with absolute certainty, but if the answer is incorrect, the algorithm has \(\frac{1}{2}\) probability of outputting no .
Randomized algorithms with polynomial time runtime complexity, whose output is always correct, are said to be in ZPP, or zero-error probabilistic polynomial time algorithms. ZPP, then, are Las Vegas algorithms which are both in RP and in co-RP. Lastly, the class of problems for which both YES and NO-instances are allowed to be identified with some error, commonly known as Monte Carlo algorithms, are in the complexity class called BPP, bounded-error probabilistic polynomial time.
Derandomization
It is worth mentioning that a considerable amount of mathematicians and theoreticians are working on producing an efficient derandomization process, whereby all the randomness is removed from an algorithm while keeping runtimes the same. Although a few techniques have been developed, whether \(P = BPP\), where \(P\) is a polynomial-time algorithm, is still an open problem. Most theoreticians believe that \(P \neq BPP\), but that has not been formally proven yet.
For a more technical reference on the question of the implications involving \(P=BPP\), refer to the paper In a World of P=BPP, by Oded Goldreich’s, professor of Computer Science at the Faculty of Mathematics and Computer Science of Weizmann Institute of Science, Israel.
Additional Examples
In this day and age, efficiency and performance make or break a product; therefore, algorithm designers focus their attention on reducing computational time, frequently turning to randomized algorithms. The following are a few common randomized algorithms encountered in many popular computer science and math courses, as well as common software and hardware programs encountered on a daily basis.
Primality Testing
Testing whether a number is prime or composite has been a problem spanning several centuries, and is still a problem today as modern cryptographic techniques securing important information, amongst many other techniques, depend on it.
Primality Testing was one of the first randomized algorithms formally developed in the 1970s, however, the idea spans as far back as the 1600s, when Fermat published his Little Theorem, which helps compute powers of integers with modulo prime numbers.
Randomized algorithms are used to perform primality testing in order to avoid a brute force search, which would consist of a time consuming linear search of every prime number leading up to the number at hand.
Randomized Minimum Cut
The Max-Flow Min-cut algorithm is another basic randomized algorithm applied on network flow and general graph problems. The goal is to find the smallest total weight of edges which, if removed, would disconnect the source from the sink in a max-flow network problem. Due to the fact that every edge must be checked in order to confidently assure that the right answer is found, randomized algorithms are developed in order to expedite the process by acknowledging that there is a slight probability that the algorithm outputs an incorrect answer. For more information on the most famous randomized algorithm for a minimum cut in a graph, see the Ford-Fulkerson Algorithm.
Frievalds’ Algorithm for Matrix Product Checking
Given three \(n\) x \( n\) matrices, A, B, and C, a common problem is to verify whether \(A \times B = C\). Since matrix multiplication is a rather costly process and checking the stated equality would require term-by-term comparisons of both sides of the equation, randomized algorithms have been developed in order to avoid this brute force method of checking the equality. The most famous algorithm is named after Rusins Frievalds, who realized that by using randomization, he could reduce the running time of this problem from brute force matrix multiplication using Strassen’s algorithm, taking a runtime of \(O(n^{2.37})\), to \(O(k n^2)\), where k is the number of times the algorithm is executed. Although Frievald’s algorithm is fast, it is performed assuming a probability of failure of less than \(2^{-k}\).
Bibliography
Demaine, E., Devadas, S., Lynch, N. Design and Analysis of Algorithms. MIT Open Courseware. Retrieved June 6th, 2016, from http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-046j-design-and-analysis-of-algorithms-spring-2015/
Cormen, T.; Leiserson, C.; Rivest, R.; Stein, C. Introduction To Algorithms, Second Edition. Cambridge, Massachusetts: MIT Press, 1990.
References
- Zhigilei, L. Computational-Materials-Group-Notes. Retrieved June 11, 2016, from http://www.people.virginia.edu/~lz2n/mse524/notes-2003/MC.pdf
- Jo, C. Monte-Carlo. Retrieved June 9, 2016, from https://simple.wikipedia.org/wiki/Monte_Carlo_algorithm#/media/File:Pi_30K.gif
- University of British Columbia, . Cached-Correspondence-Between-Professors. Retrieved June-2016, from www.cs.ubc.ca/spider/hoos/Publ/aaai99-pac.ps
- Rabin, M. (2014). Classifying-Problems-into-Complexity-Classes. Advances-in-Computers, Vol.-95, 239-292.
{kind=link}