Social Networks
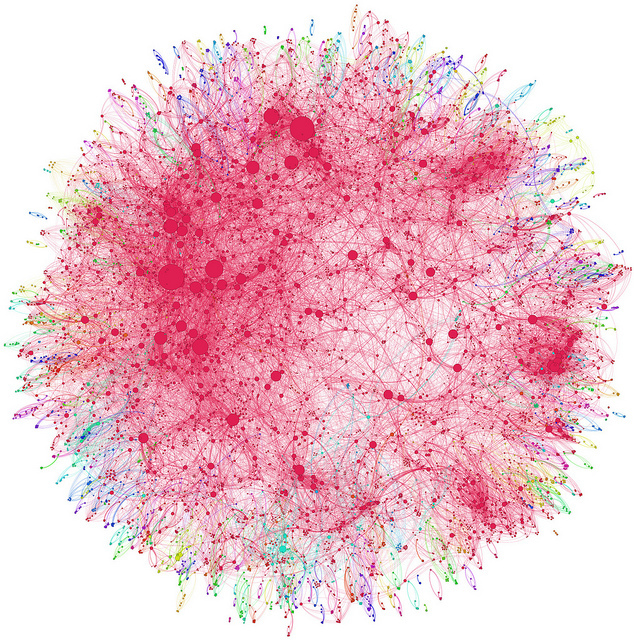 Co-authorship network map of physicians publishing on hepatitis C by Andy Lamb [1]
Co-authorship network map of physicians publishing on hepatitis C by Andy Lamb [1]
A social network graph is a graph where the nodes represent people and the lines between nodes, called edges, represent social connections between them, such as friendship or working together on a project. These graphs can be either undirected or directed. For instance, Facebook can be described with an undirected graph since the friendship is bidirectional, Alice and Bob being friends is the same as Bob and Alice being friends. On the other hand, Twitter can be described with a directed graph: Alice can follow Bob without Bob following Alice.
Social networks tend to have characteristic network properties. For instance, there tends to be a short distance between any two nodes (as in the famous six degrees of separation study where everyone in the world is at most six degrees away from any other), and a tendency to form "triangles" (if Alice is friends with Bob and Carol, Bob and Carol are more likely to be friends with each other.)
Social networks are important to social scientists interested in how people interact as well as companies trying to target consumers for advertising. For instance if advertisers connect up three people as friends, co-workers, or family members, and two of them buy the advertiser's product, then they may choose to spend more in advertising to the third hold-out, on the belief that this target has a high propensity to buy their product.
Social scientists can also use social networks to model the way things made by people connect. Pages on the internet and the links between them form a social network in much the same way as people form networks with other people. Also, counter-intelligence agencies have used cell-phone data and calls to map out terrorist cells.
The image to the right shows the connections between different physicians who co-author papers on hepatitis C, for instance showing that two people who coauthored one paper, also mutually coauthored separate papers with another physician.
Random Graphs
To simulate how a social network forms, mathematicians use random graphs that model how people make connections as they enter the network.
Random graphs are developed by adding nodes to the graph one by one and randomly adding edges between nodes according to a probabilistic rule. Different choices for the edge-adding rules result in graphs with very different structure. The simplest type of random graph is called an Erdos-Renyi graph. When each node is added, there is a fixed probability \(p\) that any given possible edge between it and another node is added. This means that any two people are equally likely to be connected as any two other people, and having a common connection doesn’t increase the chance that you are also connected to each other. This is very different from what we observe in real social networks, where people tend to cluster together.
 Take a simple model of a social network where friendships form at random between individuals. Each person forms some number of friendships with other people, \(k_i\). The average number of friendships that any given person makes is then \(\frac{1}{N}\sum\limits_ik_i = \langle k \rangle\).
Take a simple model of a social network where friendships form at random between individuals. Each person forms some number of friendships with other people, \(k_i\). The average number of friendships that any given person makes is then \(\frac{1}{N}\sum\limits_ik_i = \langle k \rangle\).
We call a friendship island (FI) a group of people such that everyone in the FI can reach anyone else in the FI by passing a note through mutual friends. If two people cannot send notes through a series of mutual friends, they must be in different FI.
At some value of \(\langle k \rangle\), \(\langle k\rangle_c\), the expected size of the largest FI becomes \(\infty\). What is the value of \(\langle k \rangle_c\)?
Notes and assumptions
- There are infinitely many people in the population.
In real life, people that have more friends are more likely to get more friends. This behavior is known technically as "preferential attachment," or informally as the "rich get richer effect." The simplest model that captures this feature is called a Barabasi-Albert graph. A Barabasi-Albert graph begins with a set of \(N\) completely connected nodes. Every time a node is added, a fixed number \(m\) of edges connected to that node are also added. (In contrast, the Erdos-Renyi model adds a variable number of edges at each step.) These nodes connect to other nodes with probability directly proportional to the number of edges the other node already has. This number is known as the degree \(k_i\) of node \(i\). Specifically, the probability \(p_i\) of connecting to node \(i\) is given by
\[p_i = \frac{k_i}{\sum_{j=1}^{N} k_j}.\]
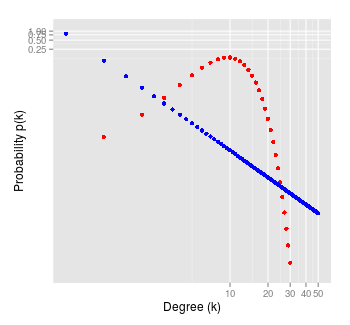 Example degree distributions for Erdos-Renyi (red) and Barabasi-Albert (blue) graphs.
Example degree distributions for Erdos-Renyi (red) and Barabasi-Albert (blue) graphs.
The denominator is simply the total degree of all nodes in the graph. Note that this is equal to twice the total number of edges, since each edge is counted once for each endpoint.
One of the most important properties of a graph is its degree distribution- a function giving the number of nodes with degree \(k\). Barabasi-Albert graphs have degree distribution \(p(k) \propto k^{-3}\), while Erdos-Renyi graphs have a binomial degree distribution. This means that Barabasi-Albert graphs have a "longer tail" than Erdos-Renyi graphs: they have many more nodes with a very high degree.
Functions of the form \(p(k) \propto k^{-c}\), where \(c\) is a constant, are called power laws. Networks with power law degree distributions are often also called scale-free. This is because they look the same at all magnitudes. If \(p(k) \propto k^{-c}\), then multiplying \(k\) by a constant \(a\) gives \(p(ak) \propto (ak)^{-c} = a^{-c}k^{-c} \propto k^{-c}\). The scale factor \(a\) doesn’t change the shape of the distribution. In this way, social networks are like fractals. When you zoom in or out on the network, it looks roughly the same.
Because power laws have such elegant properties, they have been used to describe many physical phenomena, from the number of links that a website has, to the number of citations a paper gets, to the number of other proteins a particular protein interacts with [1].
In a social network modeled with a Barabasi-Albert random graph, what is the average ratio of the number of people with one friend to the number of people with three friends?
It’s A Small World
Social networks tend to be relatively small. It only takes a couple friends of friends to get to just about everyone you'll meet. One measure of the size of a graph is the average path length between any two points in the network. The path length between two nodes in a graph is the minimum number of edges that would need to be crossed in order to get from one node to the other.
A whimsical popular application of path length is the "Bacon number" for film actors. Kevin Bacon himself has a Bacon number of 0. Everyone who has acted in a film with Kevin Bacon has a Bacon number of one. Everyone who has acted with someone with a Bacon number of one has a Bacon number of two, and so on. Another way to put this is that an actor's Bacon number is the path length from them to Kevin Bacon, where the edges represent acting together in a film.
Similarly, in mathematics, a mathematician's Erdos number is the path length between them and famous mathematician Paul Erdos in a graph where edges represent co-authorship. The Erdos-Renyi random graph described above is named after Paul Erdos.
The average path length in a Barabasi-Albert graph grows proportional to \(\text{log}(N)\), the logarithm of the number of nodes in the network. This means that the distance between nodes grows very slowly as more nodes are added. In the real world, though, the average distance can even shrink while the network grows.
In 2011, when Facebook had 721 million users, the average distance between two users was 4.74. In 2016, with 1.59 billion users, the average distance went down to 4.5 [2]. This difference between model and reality comes from the assumption that each new node makes a fixed number of connections with other nodes. If the number of new connections per node grows, then the average distance will go down (since the nodes are more connected).
If people did join Facebook in the way modeled by a Barabasi-Albert graph and the average path length with 721 million users was 4.74, what would the average path length between two users be in 2016 with 1.59 billion users? (Round your answer to two decimal places.)
The Friendship Paradox
Social networks with power law degree distributions have the peculiar feature that for most nodes in the network, the friends of that node have on average more friends than the node itself [3]. This result, known as the Friendship Paradox, arises because nodes will preferentially associate with nodes that already have a high degree.
Researchers have also found a Generalized Friendship Paradox in real-world social networks that extends to even more properties, like wealth and happiness. A person’s friends are, on average, richer and more happy than they are [4]. Unlike the Friendship Paradox, this is not a feature of any scale-free network, since it talks about properties other than those encoded by the network. However, it reflects something about the way people interact in real life.
More Problems
 Ever wonder how Facebook suggests "People you may know"? One of the first (and simplest) algorithms that is used, is to look for strangers with whom you have many mutual friends.
Ever wonder how Facebook suggests "People you may know"? One of the first (and simplest) algorithms that is used, is to look for strangers with whom you have many mutual friends.
For example, if you and Colin are not friends on Facebook yet, but both of you are friends with Belinda, then {you, Belinda, Colin} form a Friend Suggestion Triangle (FST). The more FST's that exist, the more strangers Facebook can suggest with greater confidence that you might know them.
Out of a group of 10 people, what is the maximum number of FST's that exist?
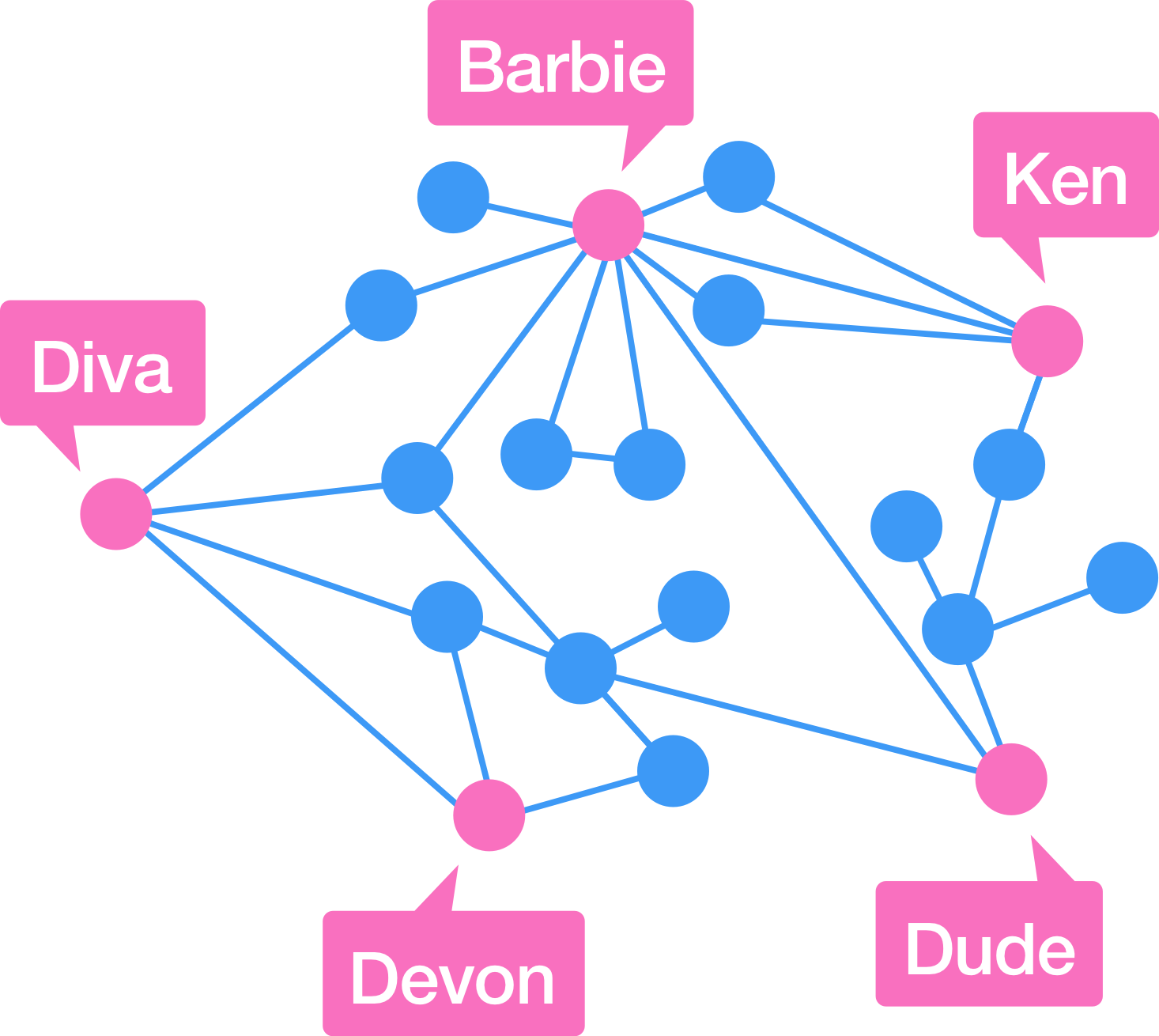 Here is a network graph constructed with data from Facebook of 20 people and all of the mutual friendship connections among them. Clearly Barbie has the most friends to invite to her parties (9), but if invitations go out not only to friends but also to all friends of friends, then whose party will have the most invites?
Here is a network graph constructed with data from Facebook of 20 people and all of the mutual friendship connections among them. Clearly Barbie has the most friends to invite to her parties (9), but if invitations go out not only to friends but also to all friends of friends, then whose party will have the most invites?
Notes and assumptions
- Each dot represents a person.
- Each line represents mutual friendship between the people on either end .
 Consider this mini social network of fifty people. Each person on the network is represented by an integer. The social network is represented as a matrix \(A\). If person \(i\) and \(j\) are "friends" then, \(A_{ij}=1\) else \(A_{ij}=0\). . How many mutual friends do the two people with the least number of mutual friends have?
Consider this mini social network of fifty people. Each person on the network is represented by an integer. The social network is represented as a matrix \(A\). If person \(i\) and \(j\) are "friends" then, \(A_{ij}=1\) else \(A_{ij}=0\). . How many mutual friends do the two people with the least number of mutual friends have?
Details and Assumptions
- \(A_{xx}=0\).
Citations
[1] Power Law Distributions in Empirical Data. http://arxiv.org/pdf/0706.1062.pdf Retrieved February 17, 2016.
[2] https://research.facebook.com/blog/three-and-a-half-degrees-of-separation/ Retrieved February 17, 2016.
[3] Feld, S. Why Your Friends Have More Friends Than You Do. American Journal of Sociology. Vol. 96, No. 6 (May, 1991), pp. 1464-1477. http://www.jstor.org/stable/2781907?seq=1#pagescantab_contents Retrieved February 17, 2016.
[4] How The Friendship Paradox Makes Your Friends Better Than You Are. MIT Technology Review. https://www.technologyreview.com/s/523566/how-the-friendship-paradox-makes-your-friends-better-than-you-are/ Retrieved February 17, 2016.
References
- Lamb, A. Co-authorship network map of physicians publishing on hepatitis C. Retrieved May 2, 2016, from https://www.flickr.com/photos/speedoflife/8273922515