Huffman Code
Huffman coding is an efficient method of compressing data without losing information. In computer science, information is encoded as bits—1's and 0's. Strings of bits encode the information that tells a computer which instructions to carry out. Video games, photographs, movies, and more are encoded as strings of bits in a computer. Computers execute billions of instructions per second, and a single video game can be billions of bits of data. It is easy to see why efficient and unambiguous information encoding is a topic of interest in computer science.
Huffman coding provides an efficient, unambiguous code by analyzing the frequencies that certain symbols appear in a message. Symbols that appear more often will be encoded as a shorter-bit string while symbols that aren't used as much will be encoded as longer strings. Since the frequencies of symbols vary across messages, there is no one Huffman coding that will work for all messages. This means that the Huffman coding for sending message X may differ from the Huffman coding used to send message Y. There is an algorithm for generating the Huffman coding for a given message based on the frequencies of symbols in that particular message.
Huffman coding works by using a frequency-sorted binary tree to encode symbols.

Information Encoding
In information theory, the goal is usually to transmit information in the fewest bits possible in such a way that each encoding is unambiguous. For example, to encode A, B, C, and D in the fewest bits possible, each letter could be encoded as “1”. However, with this encoding, the message “1111” could mean “ABCD” or “AAAA”—it is ambiguous.
Encodings can either be fixed-length or variable-length.
A fixed-length encoding is where the encoding for each symbol has the same number of bits. For example:
A 00 B 01 C 10 D 11 A variable-length encoding is where symbols can be encoded with different numbers of bits. For example:
A 000 B 1 C 110 D 1111
Explain why the encoding scheme below is a poor encoding.
A B C D 0 1 11 10
Let's try a few encodings:
- Write the binary encoding of the message BAC. \(\implies\) 1011
- Write the binary encoding of the message DC. \(\implies\) 1011
- Write the binary encoding of the message DDC. \(\implies\) 101011
- Write the binary encoding of the message BADBB. \(\implies\) 101011
As you can see from the encodings of the messages above, there are cases where the same binary string encodes different messages. This encoding scheme is ambiguous because after we encode one message, its binary representation is not unique to that message only. For example, with the encoding above, “BB” is encoded as “11” but “11” is also the encoding for “C”. \(_\square\)
The encoding below is unambiguous, but inefficient since there exists a shorter (and still unambiguous) encoding of these letters. Give an equivalent but shorter encoding.
A B C D 0000 0101 1010 1111
Each letter has the same number of bits that encodes it. Therefore, we know that every \(4\) bits in a string will encode a letter. Unlike the example above (with variable-length encoding), we do not have to worry about ambiguity because each letter has a unique binary assignment of the same length. For example, if B were encoded as 1 and C were encoded as 11, upon seeing a message 11 we could not tell if the sender intended to send BB or C. With the fixed-length encoding above, there is no possible overlap between encodings: 0000 will always be read as an A, and 1010 will always be read as a C.
However, these encodings are twice as long as they need to be: there is redundant information since the four-bit encodings are just the same two-bit encoding repeated.
To represent \(x\) symbols, we need \(\log_2(x)\) bits because each bit has two possible values: 1 or 0. Therefore, with \(x\) bits, we can represent \(2^x\) different symbols.
This problem has \(4\) symbols, so we only need \(\log_2(4) = 2\) bits to do this. Therefore, our encoding can be as follows:
A B C D 00 01 10 11
How many bits are needed to represent \(x\) different symbols (using fixed-length encoding)?
To represent \(x\) symbols with a fixed-length encoding, \(\log_2(x)\) bits are needed because each bit has two possible values: 1 or 0. Therefore, with \(x\) bits, \(2^x\) different symbols can be represented.
Huffman Code
Huffman code is a way to encode information using variable-length strings to represent symbols depending on how frequently they appear. The idea is that symbols that are used more frequently should be shorter while symbols that appear more rarely can be longer. This way, the number of bits it takes to encode a given message will be shorter, on average, than if a fixed-length code was used. In messages that include many rare symbols, the string produced by variable-length encoding may be longer than one produced by a fixed-length encoding.
As shown in the above sections, it is important for an encoding scheme to be unambiguous. Since variable-length encodings are susceptible to ambiguity, care must be taken to generate a scheme where ambiguity is avoided. Huffman coding uses a greedy algorithm to build a prefix tree that optimizes the encoding scheme so that the most frequently used symbols have the shortest encoding. The prefix tree describing the encoding ensures that the code for any particular symbol is never a prefix of the bit string representing any other symbol. To determine the binary assignment for a symbol, make the leaves of the tree correspond to the symbols, and the assignment will be the path it takes to get from the root of the tree to that leaf.

The Huffman coding algorithm takes in information about the frequencies or probabilities of a particular symbol occurring. It begins to build the prefix tree from the bottom up, starting with the two least probable symbols in the list. It takes those symbols and forms a subtree containing them, and then removes the individual symbols from the list. The algorithm sums the probabilities of elements in a subtree and adds the subtree and its probability to the list. Next, the algorithm searches the list and selects the two symbols or subtrees with the smallest probabilities. It uses those to make a new subtree, removes the original subtrees/symbols from the list, and then adds the new subtree and its combined probability to the list. This repeats until there is one tree and all elements have been added.
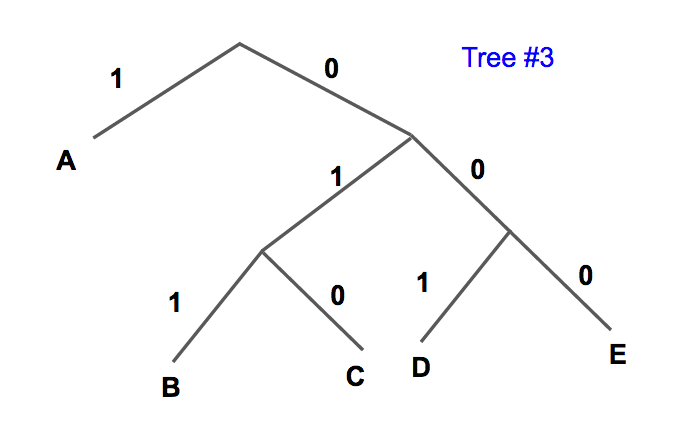
Given the following probability table, create a Huffman tree to encode each symbol.
Symbol Probability A \(0.3\) B \(0.3\) C \(0.2\) D \(0.1\) E \(0.1\) The two elements with the smallest probability are D and E. So we create the subtree:

And update the list to include the subtree DE with a probability of \(0.1 + 0.1 = 0.2:\)
Symbol Probability A \(0.3\) B \(0.3\) C \(0.2\) DE \(0.2\) The next two smallest probabilities are DE and C, so we create the subtree:

And update the list to include the subtree CDE with a probability of \(0.2 + 0.2 = 0.4:\)
Symbol Probability A \(0.3\) B \(0.3\) CDE \(0.4\) The next two smallest probabilities are A and B, so we create the subtree:

And update the list to include the subtree AB with a probability of \(0.3 + 0.3 = 0.6:\)
Symbol Probability AB \(0.6\) CDE \(0.4\) Now, we only have two elements left, so we build the subtree:

The probability of ABCDE is \(1\), which is expected since one of the symbols will occur.
Here are the encodings we get from the tree:
Symbol Encoding A 11 B 10 C 01 D 001 E 000
The Huffman Coding Algorithm
Take a list of symbols and their probabilities.
Select two symbols with the lowest probabilities (if multiple symbols have the same probability, select two arbitrarily).
Create a binary tree out of these two symbols, labeling one branch with a "1" and the other with a "0". It doesn't matter which side you label 1 or 0 as long as the labeling is consistent throughout the problem (e.g. the left side should always be 1 and the right side should always be 0, or the left side should always be 0 and the right side should always be 1).
Add the probabilities of the two symbols to get the probability of the new subtree.
Remove the symbols from the list and add the subtree to the list.
Go back through the list and take the two symbols/subtrees with the smallest probabilities and combine those into a new subtree. Remove the original symbols/subtrees from the list, and add the new subtree to the list.
Repeat until all of the elements are combined.


Huffman coding is optimal for encoding single characters, but for encoding multiple characters with one encoding, other compression methods are better. Moreover, it is optimal when each input symbol is a known independent and identically distributed random variable having a probability that is the inverse of a power of two. [1]
See Also
References
- , . Huffman Coding. Retrieved July 20, 2016, from https://en.wikipedia.org/wiki/Huffman_coding